
If you’ve connected with the Hatebase API in the past, you’ll notice a number of changes with v4; we’ve updated our authentication and added several new data attributes, including specific targeted groups, so any code you’ve written to integrate with previous versions of the API will no longer return results. If you’re new to Hatebase, the task of integrating with the service may at first appear daunting. In either case, this tutorial will help you get up and running quickly.
If you’ve integrated with other APIs in the past, feel free to skip ahead and read the full API documentation on GitHub, from which this tutorial has been adapted.
Before we begin
There are two things you’ll want to do before attempting to access the Hatebase API:
- Obtain an API key at hatebase.org/api_key — you’ll need to be logged in to do this, and the API key will only generate results if you’ve been approved for a plan. You can select a plan (while logged in) at hatebase.org/pricing
- Download some software for testing API connections. We recommend Postman, because (a) it’s free and (b) once you’ve successfully connected it can generate some preliminary code for you to start your own custom integration.
Your private API key identifies you as a unique user of the Hatebase API. Please keep it secret — don’t share it, don’t email it, and don’t embed it in browser-viewable code. If you ever believe your API key has been compromised, you can assign yourself a new one, but when you do this you’ll need to update any integration code you’ve written.
Use of the API is monitored and volume-limited. This means that if you query the API too many times, or too often, the API will shut you down, and if you continue to hammer our server with superfluous requests, this will be considered a DDoS attack and your account will be disabled.
Usually when we see too many requests against the API, it’s because you’re trying to query us in real-time — in other words, a user on your platform does something and then you immediately query Hatebase and make the user wait on results. This is an inherently flawed architecture. A safer architecture is to download Hatebase data asynchronously and store it locally, which gives you better real-time performance and doesn’t burden you (or us) with redundant data retrieval.
How it works
Querying the Hatebase API is a two-step process.
The first step is an authentication handshake in which you send us your API key and we send you back a session token (a random string of characters) that you can use for the next hour or so in lieu of continually sending us your API token. Minimizing the transit of your API token across the Internet reduces the chances of third-party interception.
The second step is the actual query itself, in which you connect to one of our endpoints, send us your session token and some input parameters, and we return a resultset. For those new to APIs, endpoints can be thought of as specific URLs which returns results. On Hatebase, all endpoints have the same URL structure:
https://api.hatebase.org/4-0/authenticate
You’ll notice the URL contains both a version number (“4-0”) and the endpoint (“authenticate”). For a list of all endpoints, consult the full API documentation on GitHub, but for the purposes of this tutorial, we’ll be using the /authenticate and /get_vocabulary endpoints.
Authenticating
Configure Postman as follows. You’ll obviously want to substitute your own API key for “abc123”.
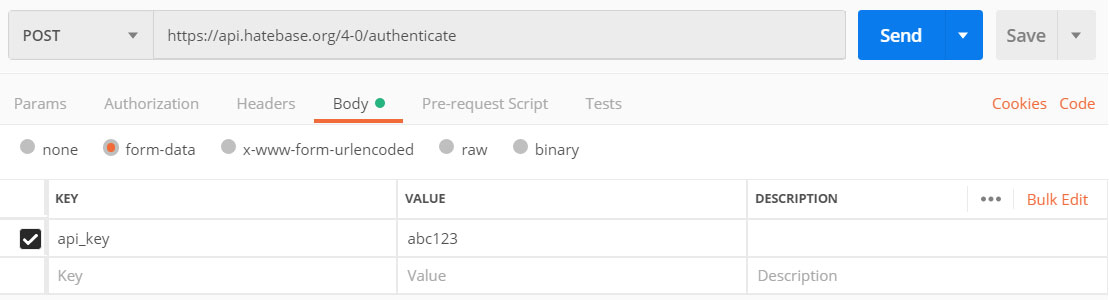
Postman will then return the following result:
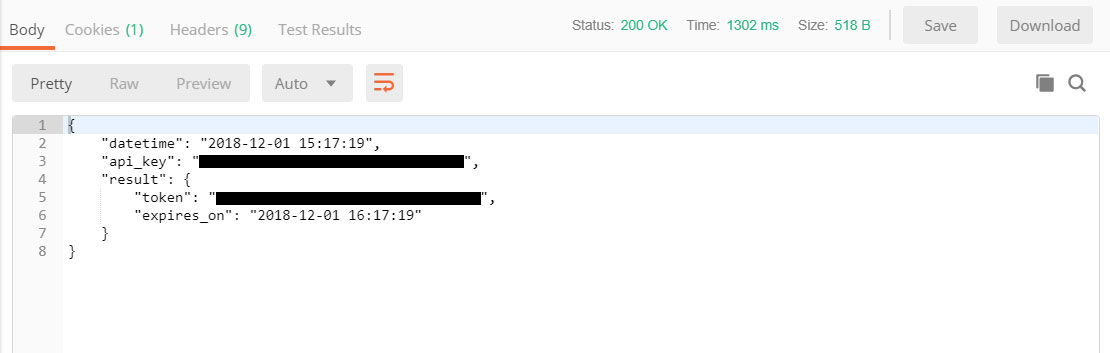
The returned token is your session token and is good for an hour, which should be more than enough time to query whatever data you need. If your session token does expire, you can simply reauthenticate to obtain a new one.
Note that any results returned from the API may include warnings and/or errors. Warnings won’t impede results, but errors will. A complete list of warning and error codes is available at hatebase.org/api_error_codes.
When writing integration code, it’s imperative that you be responsive to errors and warnings, since continuing to generate error states on Hatebase can result in your account being disabled. In particular, be alert to warnings that you are approaching your query limit, or that the version of the API you’re using is approaching retirement.
The Query
Now that you have a session token, it’s time to query some actual data from the API. Configure Postman as follows. Note that the token below is the session token that was returned to you during authentication.
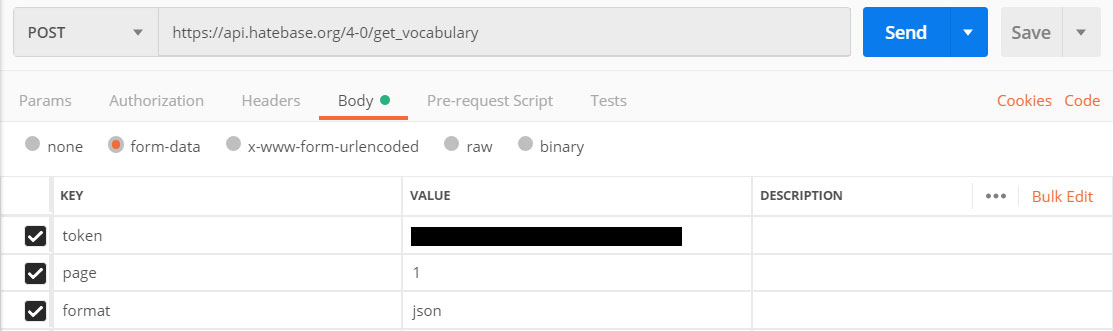
Postman will then return the following result:
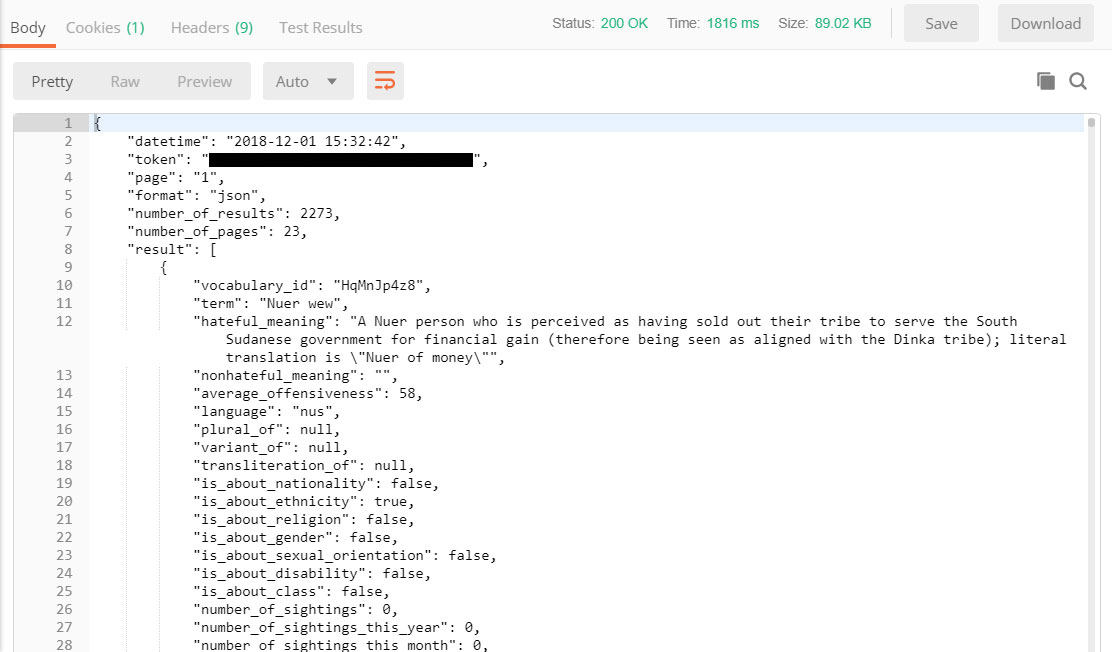
The structure of the resultset will be consistent for the life of this API version, so you can confidently code against the data types you see here.
The importance of IDs
Vocabulary and sightings both use IDs for uniqueness. These IDs are valuable for determining whether you’ve already consumed a piece of content through the API, and thus can help ensure that you’re only downloading the freshest data.
IDs are also valuable for querying additional detailed data. For example, vocabulary IDs obtained from the /get_vocabulary endpoint can be used with the /get_vocabulary_details endpoint to download more information about a specific term in the Hatebase lexicon.
Moving forward
Now that you’ve successfully connected to v4 of the Hatebase API, you’re ready to begin your own integration using code generated by Postman or your own custom code.
The full API documentation on GitHub will help answer additional questions not addressed in this tutorial.
In the months ahead, we’ll be introducing new endpoints and new data attributes, so please keep an eye on the version history in GitHub. In general, if a new version’s “characteristic” (the integer part of the number) remains unchanged, the new API version will be backwards-compatible with your version, so you won’t need to update your code unless you want to take advantage of new functionality — just update your endpoint URLs with the new version number and your code will continue to work.
We’re always interested to hear about how researchers and organizations use our data, so please consider letting us know about the project you’re working on.