
Hatebase is both a hate speech lexicon and an aggregation of real-time incident data which we call “sightings” (i.e. actual incidents of hate speech for which we can establish both time and place). Although we value our robust vocabulary of multilingual, regional hate speech, we prioritize sightings as an essential aspect of any sort of hate speech monitoring and analysis. In fact, we think of our vocabulary as a map, and of our sightings as the overlaying real-time traffic, weather, population, crime or disaster data which provides critical context.
Until recently, sightings were provided exclusively by Hatebase users through the website, but over the past couple of months we’ve refined a technology for automatically retrieving, parsing, analyzing and archiving sightings directly from Twitter, the world’s largest open social network.* We’ve achieved this by solving two problems: the low adoption of geolocation (the “where”) and the ambiguity of machine-based syntactic analysis (the “what”).
(* There are complex nuances to the notion of technology openness, but for our purposes we consider Twitter an open social network because it makes all recent data available on the open web. Other social networks such as Facebook and Google Plus restrict data within social circles and are thus of limited value for external monitoring.)
Establishing the “Where”
 Since a valid hate speech sighting must be fixed in both time and place, we rely on the timestamp Twitter provides for all tweets retrieved through its API. Establishing place, however, is tricky; it’s estimated that less than 5% of all tweets are geotagged due to opt-out geolocation, user privacy concerns and geographically unaware devices. Many Twitter users do provide freeform location data (generally cities and/or countries) in their user profiles, however, so on the assumption that most Twitter users tweet most of the time from their primary location, we’re able to extend our geolocation efforts significantly through whitelisting and reverse geolocation. Specifically, our social media robot (HateBot) examines user-provided freeform location data and:
Since a valid hate speech sighting must be fixed in both time and place, we rely on the timestamp Twitter provides for all tweets retrieved through its API. Establishing place, however, is tricky; it’s estimated that less than 5% of all tweets are geotagged due to opt-out geolocation, user privacy concerns and geographically unaware devices. Many Twitter users do provide freeform location data (generally cities and/or countries) in their user profiles, however, so on the assumption that most Twitter users tweet most of the time from their primary location, we’re able to extend our geolocation efforts significantly through whitelisting and reverse geolocation. Specifically, our social media robot (HateBot) examines user-provided freeform location data and:
- looks first in our existing data for previous freeform associations (e.g. if we’ve already manually translated a sighting in “Tronto” to Toronto, we now have good geocoordinates for “Tronto” as well)
- checks common misspellings and local spellings of country names
- scans a list of all world cities with a population exceeding 300,000 (which is our current cut-off solely for performance reasons)
- checks all North American telephone area codes to identify province/state and country
- runs whatever we’ve got through the Google Maps API as a reverse geolocation request, experimenting with levels of specificity (e.g. if “Somewheresville, Canada” isn’t geolocatable, we’ll simply geolocate to “Canada”)
As a result, we’re able to successfully geotag slightly better than 42% of all incoming tweets without human moderation.
Parsing the “What”
 Automated language analysis is a daunting challenge, not least because of the diversity of languages, misspellings and colloquialisms found on Twitter. Fortunately, our definition of a sighting doesn’t necessitate deciphering intent or sentiment, but rather just context: if a unit of vocabulary is being used (ideally non-clinically) in accordance with its meaning in Hatebase, it’s a valuable datapoint regardless of intent or sentiment since it indicates a tolerance within a speaker’s community for acceptability of usage.
Automated language analysis is a daunting challenge, not least because of the diversity of languages, misspellings and colloquialisms found on Twitter. Fortunately, our definition of a sighting doesn’t necessitate deciphering intent or sentiment, but rather just context: if a unit of vocabulary is being used (ideally non-clinically) in accordance with its meaning in Hatebase, it’s a valuable datapoint regardless of intent or sentiment since it indicates a tolerance within a speaker’s community for acceptability of usage.
For example, a non-Irish person referring to an Irish person in a pejorative manner as a “bog trotter” is clearly a valid sighting. An Irish person referring to another Irish person by this term, even in the context of camaraderie, is also a valid sighting because it indicates a tolerance for the term within the communities of the speaker and/or listener. A researcher using the term within the context of social or linguistic analysis, however, should not be considered a valid sighting. Obviously, the use of homonyms or unrelated but identically-spelled words in other languages should likewise not be considered a sighting.
![]() Enter HateBrain. Once we retrieve geotagged keyword-matching tweets through HateBot, we hand them over to our recommendation engine, which we call HateBrain. Unlike more sophisticated syntactic analysis methodologies such as sentiment analysis and statistical inference, which can suffer from a high rate of false positives, HateBrain uses a rudimentary procedural three-phase approach. Each phase employs multiple “tests” to determine whether to capture a tweet as hate speech, delete it or pass it along for human moderation. We’ve found that this testing mesh does a surprisingly good job of classifying tweets correctly, perhaps since each test can be relatively conservative in its analysis.
Enter HateBrain. Once we retrieve geotagged keyword-matching tweets through HateBot, we hand them over to our recommendation engine, which we call HateBrain. Unlike more sophisticated syntactic analysis methodologies such as sentiment analysis and statistical inference, which can suffer from a high rate of false positives, HateBrain uses a rudimentary procedural three-phase approach. Each phase employs multiple “tests” to determine whether to capture a tweet as hate speech, delete it or pass it along for human moderation. We’ve found that this testing mesh does a surprisingly good job of classifying tweets correctly, perhaps since each test can be relatively conservative in its analysis.
Here’s how HateBrain works:
- Phase 1: Apply deletion rules. We’ve identified certain language patterns which tend to indicate that a given usage isn’t hate speech, such as when a term is preceded by “the phrase,” “define” or “spell,” denoting a probable clinical usage.
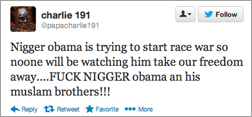
- Phase 2: Apply vocabulary rules. Certain unambiguous terms in our database (e.g. “nigger”) are always used in a valid context and can be reliably classified without further tests. Similarly, certain terms are unambiguously used in certain countries (e.g. “bogan” in Australia or New Zealand, “kurombo” in Japan, “Bazi” in Germany), and can be reliably classified based on geotagging.
- Phase 3: Apply capture rules. This phase contains the greatest number of tests, such as looking for escalation words (e.g. “fuck,” “idiot,” “Hitler,” “shut up”), xenophobic references (e.g. “foreign,” “go back,” “illegal,” “ancestry”) and individualization (e.g. “you’re a,” “is a,” “such a”). We also test the history of the term (a prior capture-to-delete ratio of 9:1 is an indicator of a likely slur), and the history of the author (on the assumption that a person who’s used hate speech before will use it again).
As a result of this methodology, we’ve been able to successfully classify 37% of all incoming tweets without human moderation.
Although we’re pleased with the success of this approach so far, there remain some drawbacks (beyond the 63% of geotagged tweets which are left in the queue for human moderation). Our language rules currently skew English, for instance. Also, a high incidence of machine-parsed hate speech tells us not only about the volatility of people and cultures in a given region, but about Internet connectivity and Twitter penetration. We also do have a small number of false positives, some of which are caught by human moderators, some not. Finally, 37% (tweets analyzed) multiplied by 42% (tweets geotagged) means that we’re only really automating the handling of 15% of all keyword-matching tweets, which doesn’t sound like a great deal of efficacy.
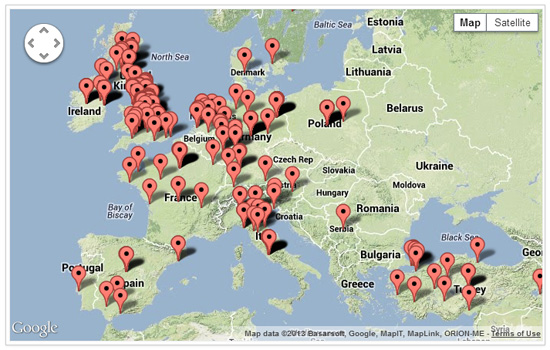
It’s important to consider the volume of data being handled, however. We’re acquiring roughly 7,500 tweets per day. So processing 15% of these results in over 1,000 tweets per day. Assuming a roughly 2:1 capture-to-delete ratio, that means we’re acquiring 750 sightings per day — or 23,000 per month, or nearly 300,000 per year. This is a substantial amount of data for analysis, and an increasingly meaningful picture of regionalized hate speech.
Areas of Opportunity
We’re eager to work with organizations and communities which can help us refine our vocabulary and language-parsing rules (particularly non-English). We’re also enthusiastic at the prospect of working with data scientists specializing in natural language processing.
Our most pressing need, however, is for consumers of our data — particularly government agencies and active, data-focused NGOs. All Hatebase vocabulary and sightings are immediately accessible through our open API, so please seed the link to this blog post to anyone who might benefit from our growing dataset.